Indexování XML dat.
Intro
Cílem je navrhnout datové struktury pro efektivní vyhodnocování dotazů jazyka
XPath nad XML daty. V první fázi se omezíme pouze na XML dokumenty, které
mají stromovou strukturu (tj. jsou zde zakázány atributy typu reference).
Reprezentace XML dokumentu
XML dokument reprezentujeme jako orientovaný graf. Jeho uzly jsou obsahy
elementů, hodnoty atributů, komentáře, textové uzly, ... . Jeho orientované
hrany označují vztahy rodič->dítě a každá hrana je označena řetězcem, který
určuje typ elementu nebo atributu, do kterého vede. Uvažujeme zatím pouze
XML dokumenty, jejichž reprezentací je strom.
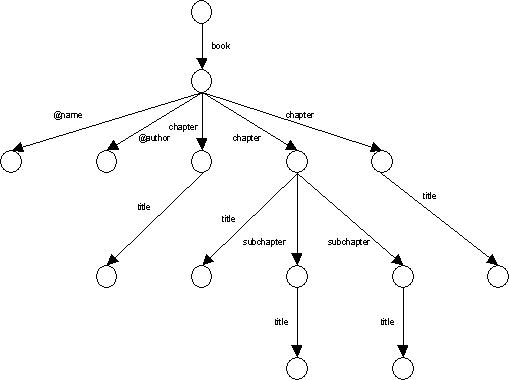
Příklad XML dokumentu a jeho reprezentace jako orientovaného grafu (pouze stromová struktura):
<book name="BookName1" author="Author1">
<chapter>
<title>Introduction</title>
</chapter>
<chapter>
<title>Story</title>
<subChapter>
<title>Part 1</title>
</subChapter>
<subChapter>
<title>Part 2</title>
</subChapter>
</chapter>
<chapter>
<title>Index</title>
</chapter>
</book>
|
|
Reprezentace XPath dotazu
Každý dotaz v jazyce XPath lze převést na normální tvar (nonabbreviated syntax).
Normální tvar je buď absolutní nebo relativní cesta. V obou
případech se cesta skládá ze Steps a každý Step je typu AxisStep nebo
GeneralStep. GeneralStep typ zatím nebudeme uvažovat. AxisStep je pak jeden
Step cesty v tomto tvaru:
Axis? NodeTest StepQualifiers.
Uvažujme pouze dotazy, jejichž Steps mají Axis = child, attribute nebo
descendant-or-self. Navíc nechť StepQualifiers jsou pouze tvaru PathExpr.
Dotaz v tomto tvaru budeme označovat jako TreeQuery.
Nechť Q je dotaz ve tvaru TreeQuery. Potom můžeme tento dotaz rozložit na
MainPath a SubPathSequence. MainPath vznikne z Q odstraňením části
StepQualifier z každého Step. MainPath budeme reprezentovat grafem typu
cesta, kde vrcholy jsou obsahy elementů či atributů v cestě a hrany opět
vyjadřují příbuzenské vztahy. Každá hrana má Label, který specifikuje typ
elementu či atributu, do kterého vede. Pro hrany zavedeme kromě zobrazení
množina hran->množina Labels ještě zobrazení množina hran->množina os, které
každé hraně přiřadí právě jednu hodnotu z {child, attribute, descendant-or-self}.
Každý StepQualifier, který jsme vyjmuli z nějakého Step dotazu Q je opět dotaz.
Pro každý takový StepQualifier SQ zkonstruujeme rekursivně graf G(SQ). Nakonec
pro každý Step v MainPath přidáme hranu z uzlu v MainPath do kořene grafu
příslušného StepQualifier. Tím vzniká rekurzivně orientovaný strom.
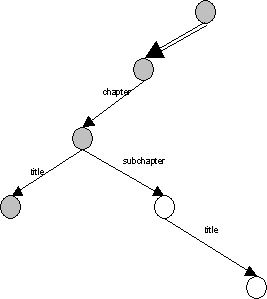
Příklad XPath dotazu a jeho grafu:
//chapter[subchapter/title]/title
Interpretace : všechny titles takových kapitol, které mají subchapter s titlem.
Reprezentace : MainPath je //chapter/title, jediná SubPath je ./subchapter/title a přísluší
k uzlu, do kterého vede hrana chapter.
|
|
Indexová struktura
Nejdříve uvažujme pouze stromovou strukturu XML dokumentu. Indexová
struktura vyjde z indexu APEX, kterou rozšíříme o číslování uzlů, které nám
umožní v konstantním čase zjistit pro dva dané uzly z XML dokumentu, zda je
jeden předkem druhého. Číslování uzlů bude vycházet z cest v XML dokumentu.
RootedPath
RootedPath je absolutní cesta, tj. začíná v kořenu. V příkladě to je např. cesta
/book/chapter/title.
Číslování uzlů XML dokumentu
Cílem je přiřadit každému uzlu v grafu XML dokumentu jednoznačný identifikátor
v rámci dokumentu. V kombinaci s DocID získáme jednoznačnou identifikaci uzlu
v celém systému. Výsledná struktura také musí umožňovat převod z logických
identifikátorů uzlů na jejich fyzické identifikátory Storage system (u těch uzlů
grafu, které mají obsah k uložení, např. uzly obsahů atributů, textové uzly, ...).
To bude provedeno pomocí BTree organizovaného podle logických id, který je bude
mapovat na fyzická id.
Každá RootedPath dostane jednoznačný identifikátor. Předpokládáme stromovou
strukturu XML dokumentu, takže každý XML uzel leží právě na jedné RootedPath.
Nechť PN je množina všech podmnožin množiny uzlů XML dokumentu, nechť RP je
množina všech RootedPaths XML dokumentu. Nechť R : RP -> PN je zobrazení, které
každé RootedPath z RP přiřazuje množinu všech uzlů XML dokumentu, které leží
na této RootedPath. Vezmeme-li obor hodnot R, získáme disjunktní množiny,
jejichž sjednocením je původní množina všech uzlů XML dokumentu. Uzly v jedné
množině z tohoto oboru hodnot potřebujeme dále rozlišit. K rozlišení využijeme
pořadí uzlů vzhledem k rodičovskému uzlu. Tím vznikne druhá část ID uzlu, tuto
část budeme nazývat HierarchyNumber, první část (Id cesty) označíme jako
RootPathNumber. Výsledné Id daného uzlu je potom dvojice RootPathNumber, HierarchyNumber.
Určení HierarchyNumbers pro uzly na dané RootPath RPM probíhá následovně:
- Vezmeme podgraf RPG grafu G XML dokumentu. RPG vznikne vybráním všech instancí RPM z grafu G.
- Inicializace : Vytvoř spojový seznam HierarchyNumbers bitových kódů s jedním kódem o délce 0.
-
RPG procházíme od dětí kořene prohledáváním do šířky a pro každý uzel z R(RPM) vytvoříme HierarchyNumber. Pro každou hladinu
- Rozděl uzly na hladině do skupin takových, že v jedné skupině budou uzly se stejným rodičem (z předchozí hladiny).
- Vyber skupinu MS s největším počtem uzlů, difNum = log|MS|.
-
Pro každou skupinu S:
- Přiraď uzlům z S pořadová binární čísla délky difNum.
- Vyjmi binární kód BK rodiče uzlů z S z HierarchyNumbers a na jeho pozici vlož do HierarchyNumbers spojový seznam z binárních kódů uzlů z S, které vzniknou spojením BK a pořadového binárního čísla daného uzlu.
- Po průchodu poslední hladinou grafu RPG je v HierarchyNumbers binární kód pro každý uzel z R(RPM) zároveň jeho HierarchyNumber.
Tato konstrukce by se dala reálně provést v jednom průchodu celého grafu XML dokumentu najednou,
tady sem to udělal takhle míň efektivně, aby to nebylo tak složitý.
Pro každé RootPathNumber musíme uložit také posloupnost difNums, abychom věděli, jak
dané HierarchyNumber rozdělit.
Pro dané dva uzly a pro určení, zda jeden je předkem druhého potom stačí rovnost
jejich RootPathNumbers a to, že HierarchyNumber jednoho uzlu je prefixem
HierarchyNumber druhého uzlu. Pro určení, zda jeden uzel je přímým potomkem
druhého uzlu je toto číslování samotné nedostačující, protože mohou nastat
případy, kdy k rozlišení je třeba 0bitů (difNum = 0). Potom nejsme schopni
určit počet hladin mezi uzly. To se dá vyřešit dvěma způsoby. První způsob
využije kódování takové, že na jedné hladině nepoužijeme difNum bitů, ale
difNum+1. Druhý způsob předpokládá existenci samostatné struktury, která
realizuje zobrazení přiřazující danému uzlu seznam jeho dětí.
To, že dokážeme v konstantním čase pro dané dva uzly zjistit, zda jeden
je předkem druhého je velmi důležité pro indexovou strukturu APEX. APEX obsahuje
následující údaje:
-
Pro každý Label (tj. typ elementu či atributu) udžuje seznam hran, které
jsou ohodnoceny tímto Label. V příkladě například pro Label chapter
celkem 3 hrany=dvojice uzlů.
-
Dál pro často dotazované cesty (to co je často dotazovaná cesta se dá
nastavit parametrem) udržuje počáteční a koncové uzely instancí těchto
cest. Např. je-li často dotazována chapter/subchapter, pak pro ní drží
dvě dvojice uzlů (začátek cesty a konec cesty).
Přijde-li dotaz s nějakou cestou, kterou nemá APEX naindexovánu, má naindexovány
alespoň jednotlivé kroky. Musí tedy nalézt nejdelší naindexované části a ty
pospojovat. K tomu právě využije HierarchyNumbers, ze kterých v konstantním
čase určuje vztah předek/potomek, vztah rodič/dítě určí v konstantním čase ve variantě
1 a asi v logaritmickém ve variantě 2.
Vyhodnocení dotazu ve tvaru TreeQuery popíšu až k tomu zase sednu. Bude to ale
právě částečné vyhodnocení pomocí APEX a spojení výsledků pomocí HierarchyNumbers.
Dál se bude muset dořešit update. Ten by měl být efektivnější než jiné
druhy číslování.